Code
if(!require("pacman")){install.packages("pacman")}; library(pacman)
pacman::p_load(readxl, tidyverse, survey, purrr, srvyr, knitr, shinydashboard,shiny)Análise dos dados com o R - EM CONSTRUÇÃO…
Este artigo foi reescrito em Sexta-Feira, 03 de maio de 2024.
![]()
O código começa carregando os dados necessários para a análise do site do Data Senado. Em seguida, são realizadas algumas transformações nos dados, como mudança de nomenclatura e agrupamento por região, sexo, idade, entre outros, para facilitar a compreensão e análise futura.
Em seguida, o código realiza uma ponderação dos dados, utilizando o pacote survey, ajustando os pesos das observações para que reflitam a distribuição da população.
Após a ponderação, são realizadas análises descritivas e multivariadas dos dados. São apresentadas visualizações sobre as principais preocupações da população brasileira, opiniões sobre temas como redução da maioridade penal e criação de impostos sobre grandes fortunas, bem como análises estratificadas por sexo, idade, voto nas últimas eleições e religião.
Essas análises visam fornecer insights sobre as opiniões e preocupações da população brasileira em relação a diversos temas.
Os dados utilizados nesta análise estão disponíveis no site do Data Senado. Você pode acessar os dados, documentos técnicos e alguns dos blocos de códigos utilizados nesta análise clicando aqui.
Instalando e carregando pacotes
if(!require("pacman")){install.packages("pacman")}; library(pacman)
pacman::p_load(readxl, tidyverse, survey, purrr, srvyr, knitr, shinydashboard,shiny)Carregando o dicionário de dados.
rm(list = ls())
DICIONARIO_DE_DADOS <- read_excel("C:/Users/welli/OneDrive/portifolio-dados.github.io/projetos-R/dados/DATASEN BR 2022 NOV BAROMETRO - DICIONARIO DE DADOS.xlsx")Carregando Microdado
df = read.csv2("C:/Users/welli/OneDrive/portifolio-dados.github.io/projetos-R/dados/DATASEN BR 2022 NOV BAROMETRO - DADOS.csv", sep = ";")Mudanca de nomenclatura das variaveis para facilitar entendimento do codigo
df <- df |>
mutate(
P02 = case_when(
P02 == 12 ~ "Acre",
P02 == 27 ~ "Alagoas",
P02 == 13 ~ "Amazonas",
P02 == 16 ~ "Amapá",
P02 == 29 ~ "Bahia",
P02 == 23 ~ "Ceará",
P02 == 53 ~ "Distrito Federal",
P02 == 32 ~ "Espírito Santo",
P02 == 52 ~ "Goiás",
P02 == 21 ~ "Maranhão",
P02 == 51 ~ "Mato Grosso",
P02 == 50 ~ "Mato Grosso do Sul",
P02 == 31 ~ "Minas Gerais",
P02 == 15 ~ "Pará",
P02 == 25 ~ "Paraíba",
P02 == 41 ~ "Paraná",
P02 == 26 ~ "Pernambuco",
P02 == 22 ~ "Piauí",
P02 == 33 ~ "Rio de Janeiro",
P02 == 24 ~ "Rio Grande do Norte",
P02 == 43 ~ "Rio Grande do Sul",
P02 == 11 ~ "Rondônia",
P02 == 14 ~ "Roraima",
P02 == 42 ~ "Santa Catarina",
P02 == 35 ~ "São Paulo",
P02 == 28 ~ "Sergipe",
P02 == 17 ~ "Tocantins",
TRUE ~ NA)) |>
mutate(
VD_REGIAO = case_when(
VD_REGIAO == 1 ~ "Norte",
VD_REGIAO == 2 ~ "Nordeste",
VD_REGIAO == 3 ~ "Sudeste",
VD_REGIAO == 4 ~ "Sul",
VD_REGIAO == 5 ~ "Centro-Oeste",
TRUE ~ NA)) |>
mutate(
V02 = case_when(
V02 == 1 ~ "Masculino",
V02 == 2 ~ "Feminino",
TRUE ~ NA)) |>
mutate(
V04 = case_when(
V04 == 1 ~ "Branca",
V04 == 2 ~ "Preta",
V04 == 3 ~ "Parda",
V04 == 4 ~ "Indígena",
V04 == 5 ~ "Amarela",
V04 == 97 ~ "Não sei/Prefiro não responder",
TRUE ~ NA)) |>
mutate(
V09 = case_when(
V09 == 1 ~ 'Católica',
V09 == 2 ~ 'Evangélica',
V09 == 3 ~ 'Espírita',
V09 == 4 ~ 'Sem religião ou crença',
V09 == 5 ~ 'Outra',
V09 == 99 ~ 'Prefiro não responder',
TRUE ~ NA)) |>
mutate(
P04 = case_when(
P04 == 1 ~ "Saúde",
P04 == 2 ~ "Emprego",
P04 == 3 ~ "Custo de vida",
P04 == 4 ~ "Corrupção",
P04 == 5 ~ "Segurança pública",
P04 == 6 ~ "Educação",
P04 == 7 ~ "Outro",
P04 == 97 ~ "Não sei/Prefiro não responder",
TRUE ~ NA)) |>
mutate(
P19 = case_when(
P19 == 1 ~ "Muito satisfeito(a)",
P19 == 2 ~ "Pouco satisfeito(a)",
P19 == 3 ~ "Nada satisfeito(a)",
P19 == 97 ~ "Não sei/Prefiro não responder",
TRUE ~ NA)) |>
mutate(
VD_IDADE = case_when(
VD_IDADE == 1 ~ "16 a 29 anos",
VD_IDADE == 2 ~ "30 a 39 anos",
VD_IDADE == 3 ~ "40 a 49 anos",
VD_IDADE == 4 ~ "50 a 59 anos",
VD_IDADE == 5 ~ "60 anos ou mais",
TRUE ~ NA_character_)) |>
mutate(
VD_VOTO.TURNO1_ = case_when(
VD_VOTO.TURNO1 == 1 ~ "Jair Bolsonaro (22)",
VD_VOTO.TURNO1 == 2 ~ "Lula (13)",
VD_VOTO.TURNO1 == 3 ~ "Outros/Branco/Nulo/Não votou",
TRUE ~ NA_character_)) |>
mutate(
VD_VOTO.TURNO2_ = case_when(
VD_VOTO.TURNO2 == 1 ~ "Jair Bolsonaro (22)",
VD_VOTO.TURNO2 == 2 ~ "Lula (13)",
VD_VOTO.TURNO2 == 3 ~ "Outros / Branco/Nulo/Não votou",
TRUE ~ NA_character_)) |>
mutate(
P06 = case_when(
P06 == 1 ~ "A favor",
P06 == 2 ~ "Contra",
P06 == 97 ~ "Não sei / Prefiro não responder",
TRUE ~ NA_character_)) |>
mutate(
P08 = case_when(
P08 == 1 ~ "A favor",
P08 == 2 ~ "Contra",
P08 == 97 ~ "Não sei / Prefiro não responder",
TRUE ~ NA_character_)) |>
mutate(
P09 = case_when(
P09 == 1 ~ "Qualquer valor abaixo de R$ 499 mil",
P09 == 2 ~ "De R$ 500 mil a R$ 999 mil",
P09 == 3 ~ "De R$ 1 milhão a R$ 9,9 milhões",
P09 == 4 ~ "De R$ 10 milhões a 49 milhões",
P09 == 5 ~ "De R$ 50 milhões a 99 milhões",
P09 == 6 ~ "Acima de R$ 100 milhões",
P09 == 7 ~ "Não sei",
P09 == 8 ~ "Prefiro não responder",
TRUE ~ NA_character_
)
)Definição das variáveis a serem usadas no raking (calibracao):
# Mudanca de nomenclatura das variaveis para facilitar entendimento do codigo
df$regiao.wgts = df$VD_REGIAO
df$sexo.wgts = df$V02
df$edu.wgts = df$VD_EDUCACAO
df$raca.wgts = df$VD_RACA
df$idade.wgts = df$VD_IDADE
df$porte.wgts = df$VD_PORTE
df$voto.turno1.wgts = df$VD_VOTO.TURNO1
df$voto.turno2.wgts = df$VD_VOTO.TURNO2
## Ponderacao ------------
# Definição das variáveis a serem usadas no raking (calibracao):
var.wgts = c("raca.wgts",
"sexo.wgts",
"idade.wgts",
"porte.wgts",
"edu.wgts",
"voto.turno2.wgts",
"voto.turno1.wgts")
# Definição das variaveis populacionais que servirao de parametro para o raking
# Essas variaveis foram extraidas da PNADC 2021-03
var.pop = c("POP_REGIAO_RACA",
"POP_REGIAO_SEXO",
"POP_REGIAO_IDADE",
"POP_REGIAO_PORTE",
"POP_REGIAO_EDU",
"POP_REGIAO_VOTO.TURNO2",
"POP_REGIAO_VOTO.TURNO1")
# Criacao da lista de referencia com os parametros populacionais a serem usados na funcao rake:
population <- list(0)
for (i in 1:length(var.wgts)) {
pop = unique(df[, c('regiao.wgts', var.wgts[i], var.pop[i])])
names(pop) <- c('regiao.wgts', var.wgts[i], 'freq')
population[[i]] <- pop
}
# Definicao das variaveis na amostra que serao usadas no rake, no formato exigido pela funcao
sample <- map(paste0("~", "regiao.wgts +", var.wgts), as.formula)
# Delineamento amostral ------------
data.svy <-
svydesign(
id = ~ ID,
weights = df$W1,
data = df,
strata = df$regiao.wgts
)
# Ponderacao Rake ------------
data.rake <-
rake(
data.svy,
sample.margins = sample,
population.margins = population,
control = list(maxit = 62)
)Teste para ver se a ponderacao acima bate com o peso calculado pelo DataSenado disponivel na base
Wrake <- data.frame(ID = data.svy$cluster, W2_teste = weights(data.rake))
summary(Wrake$W2_teste) Min. 1st Qu. Median Mean 3rd Qu. Max.
1323 31923 55903 83460 97066 1547555 summary(df$W2) Min. 1st Qu. Median Mean 3rd Qu. Max.
1323 31923 55903 83460 97066 1547555 Como os valores são iguais vamos partir para as análises
srvyr para facilitar a análisedata.rake.srvyr <- as_survey(data.rake)Qual é a maior preocupação dos cidadãos do Brasil atualmente?
preocupacao <- data.rake.srvyr %>%
group_by(P04) %>%
summarise(porcentagem = survey_prop()) |>
rename("Preocupação"=P04)
ggplot(preocupacao, aes(x = Preocupação, y = (porcentagem*100), fill = Preocupação)) +
geom_bar(stat = "identity") +
geom_errorbar(aes(ymin = (porcentagem*100) - (porcentagem_se*100), ymax = (porcentagem*100) + (porcentagem_se*100)), width = 0.4, position = position_dodge(0.9), color = "red") +
labs(title = "Principais preocupações dos respondentes", y = NULL, x = NULL) +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
scale_fill_brewer(palette = "Set3") +
geom_text(aes(label = paste0(round((porcentagem*100), 1), "%")), vjust = 3, size = 3, position = position_dodge(width = 0.9))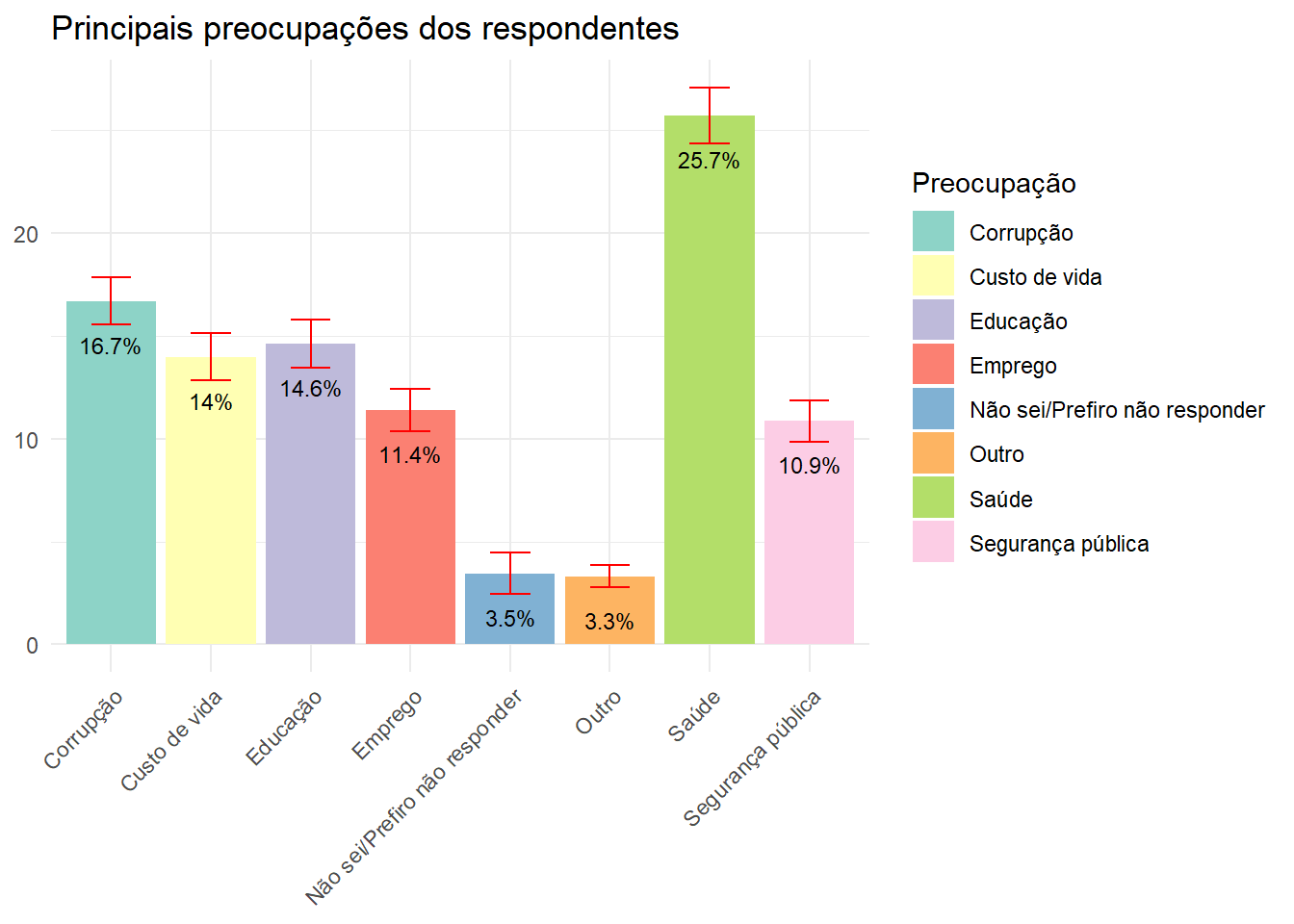
Qual é a opinião predominante da população brasileira em relação à redução da maioridade penal?
maioridADE <- data.rake.srvyr %>%
group_by(P06) %>%
summarise(porcentagem = survey_prop()) |>
rename("Opinião" = P06)
ggplot(maioridADE, aes(x = Opinião, y = (porcentagem*100), fill = Opinião)) +
geom_bar(stat = "identity") +
geom_errorbar(aes(ymin = (porcentagem*100) - (porcentagem_se*100), ymax = (porcentagem*100) + (porcentagem_se*100)), width = 0.4, position = position_dodge(0.9), color = "red") +
labs(title = "Opinião sobre a redução da maioridade penal", y = NULL, x = NULL) +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
scale_fill_brewer(palette = "Set3") +
geom_text(aes(label = paste0(round((porcentagem*100), 1), "%")), vjust = 3, size = 3, position = position_dodge(width = 0.9))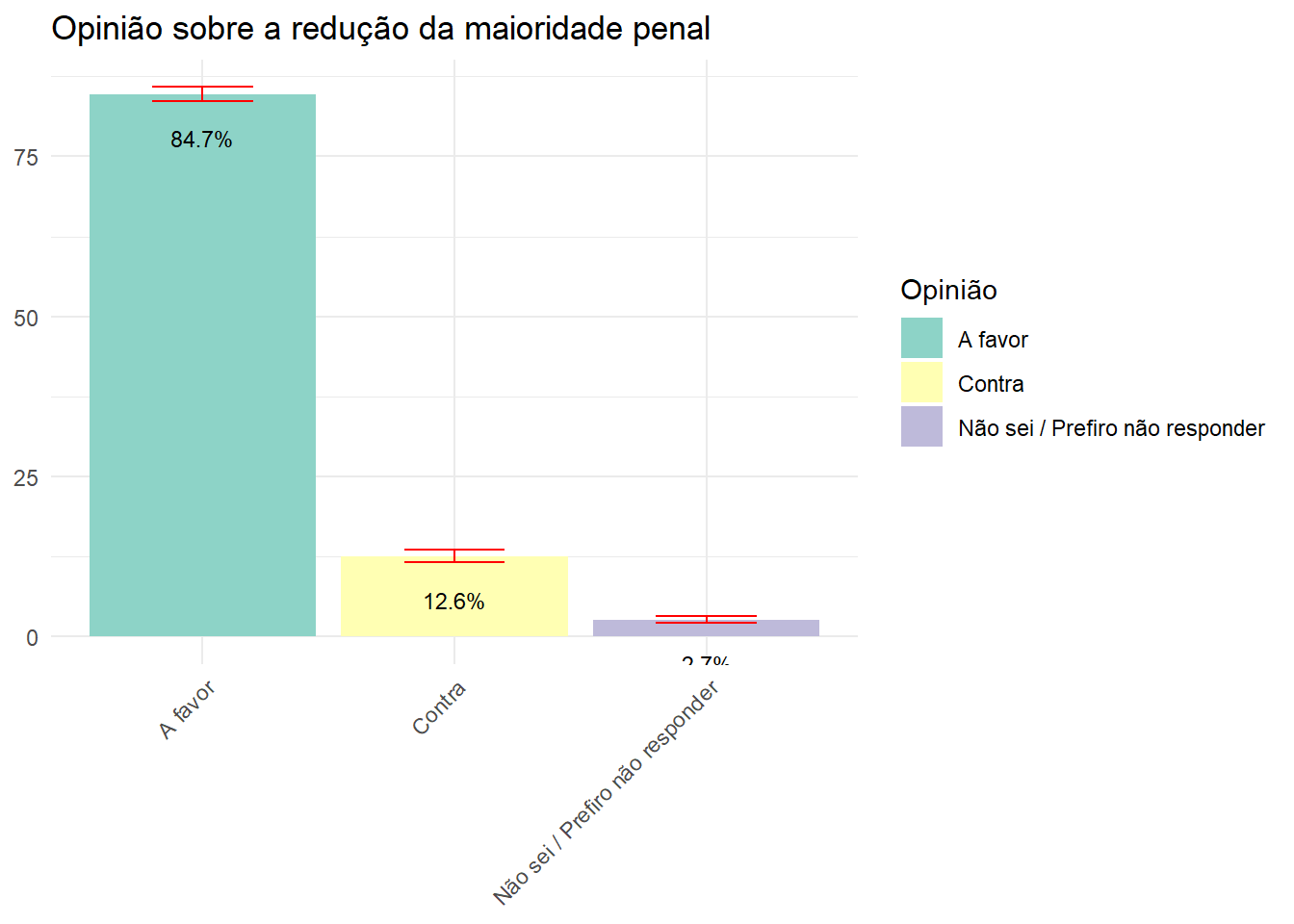
Qual é a opinião predominante da população brasileira em relação à criar impostos sobre grandes fortunas?
impo_fortuna <- data.rake.srvyr %>%
group_by(P08) %>%
summarise(porcentagem = survey_prop()) |>
rename("Opinião" = P08)
ggplot(impo_fortuna, aes(x = Opinião, y = (porcentagem*100), fill = Opinião)) +
geom_bar(stat = "identity") +
geom_errorbar(aes(ymin = (porcentagem*100) - (porcentagem_se*100), ymax = (porcentagem*100) + (porcentagem_se*100)), width = 0.4, position = position_dodge(0.9), color = "red") +
labs(title = "Opinião sobre criar impostos sobre grandes fortunas", y = NULL, x = NULL) +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
scale_fill_brewer(palette = "Set3") +
geom_text(aes(label = paste0(round((porcentagem*100), 1), "%")), vjust = 3, size = 3, position = position_dodge(width = 0.9))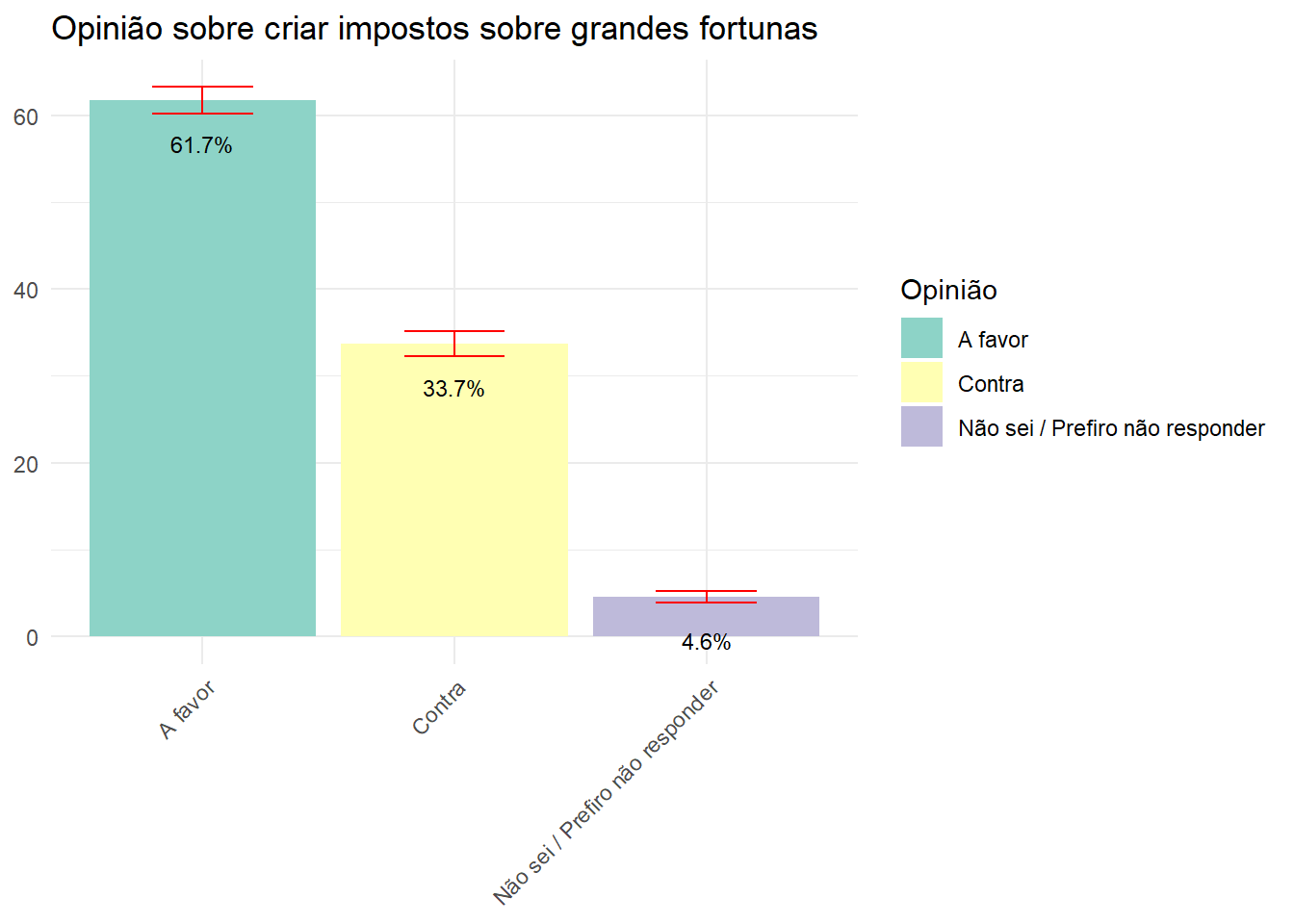
Para a população brasileira a partir de que valor seria uma grande fortuna?
fortuna <- data.rake.srvyr %>%
group_by(P09) %>%
summarise(porcentagem = survey_prop()) |>
rename("Faixa de Valores" = P09)
ggplot(fortuna, aes(x = `Faixa de Valores`, y = (porcentagem*100), fill = `Faixa de Valores`)) +
geom_bar(stat = "identity") +
geom_errorbar(aes(ymin = (porcentagem*100) - (porcentagem_se*100), ymax = (porcentagem*100) + (porcentagem_se*100)), width = 0.4, position = position_dodge(0.9), color = "red") +
labs(title = "A partir de que valor seria uma grande fortuna?", y = NULL, x = NULL) +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
scale_fill_brewer(palette = "Set3") +
geom_text(aes(label = paste0(round((porcentagem*100), 1), "%")), vjust = 3.5, size = 3, position = position_dodge(width = 0.9))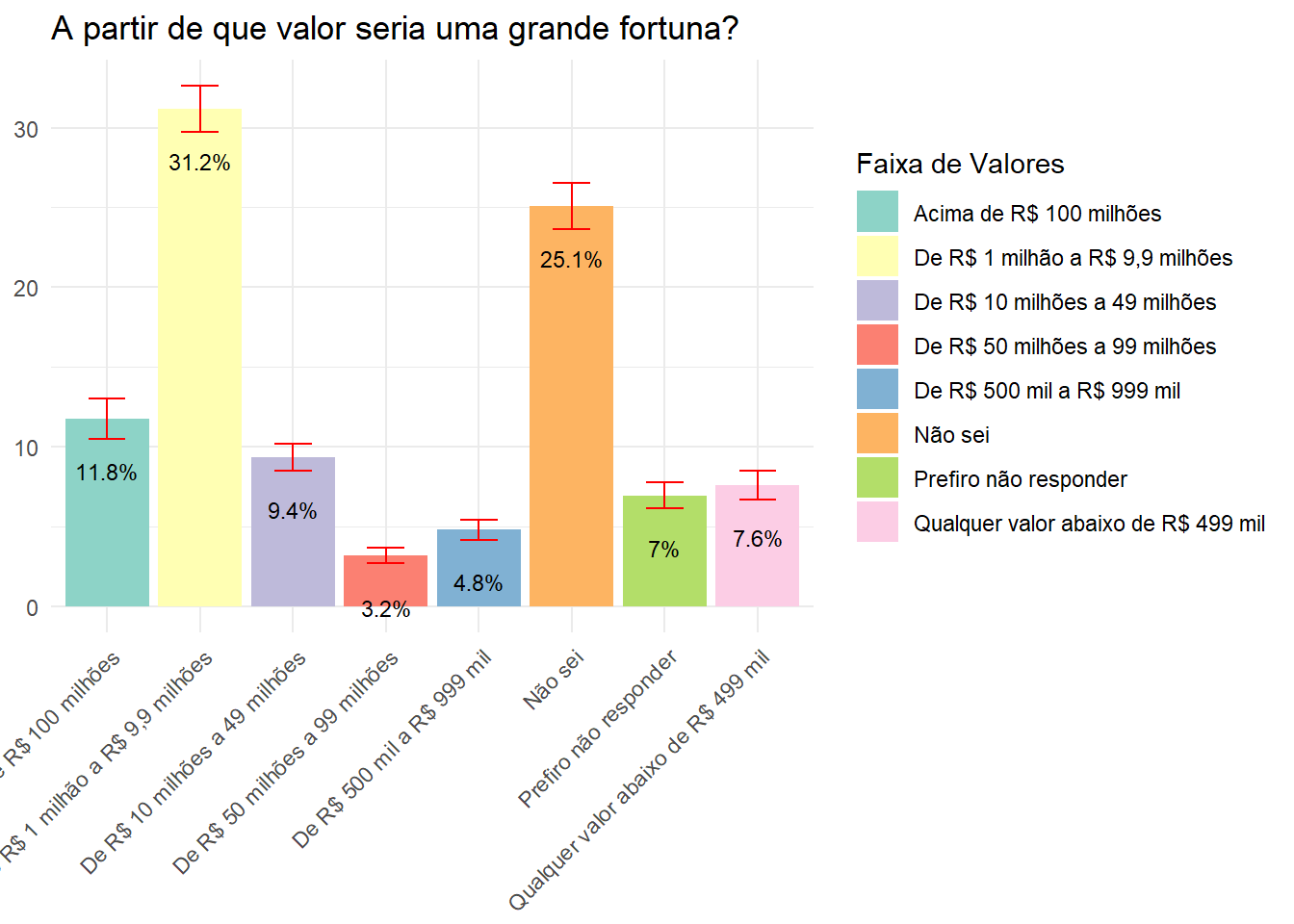
Qual a principal preocupação da população brasileira por sexo
preocupacao_por_sexo <- data.rake.srvyr %>%
group_by(V02, P04) %>%
summarise(porcentagem = survey_prop()) |>
rename("Sexo" = V02, "Preocupação" = P04)
ggplot(preocupacao_por_sexo, aes(x = Preocupação, y = (porcentagem*100), fill = Sexo)) +
geom_bar(stat = "identity", position = "dodge") +
geom_errorbar(aes(ymin = (porcentagem*100) - (porcentagem_se*100), ymax = (porcentagem*100) + (porcentagem_se*100)), width = 0.4, position = position_dodge(0.9), color = "red") +
labs(title = "Principais preocupações dos respondentes por sexo", y = NULL, x = NULL) +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
scale_fill_brewer(palette = "Set3") +
geom_text(aes(label = paste0(round((porcentagem*100), 1), "%")), position = position_dodge(width = 0.9), vjust = -0.5, size = 3)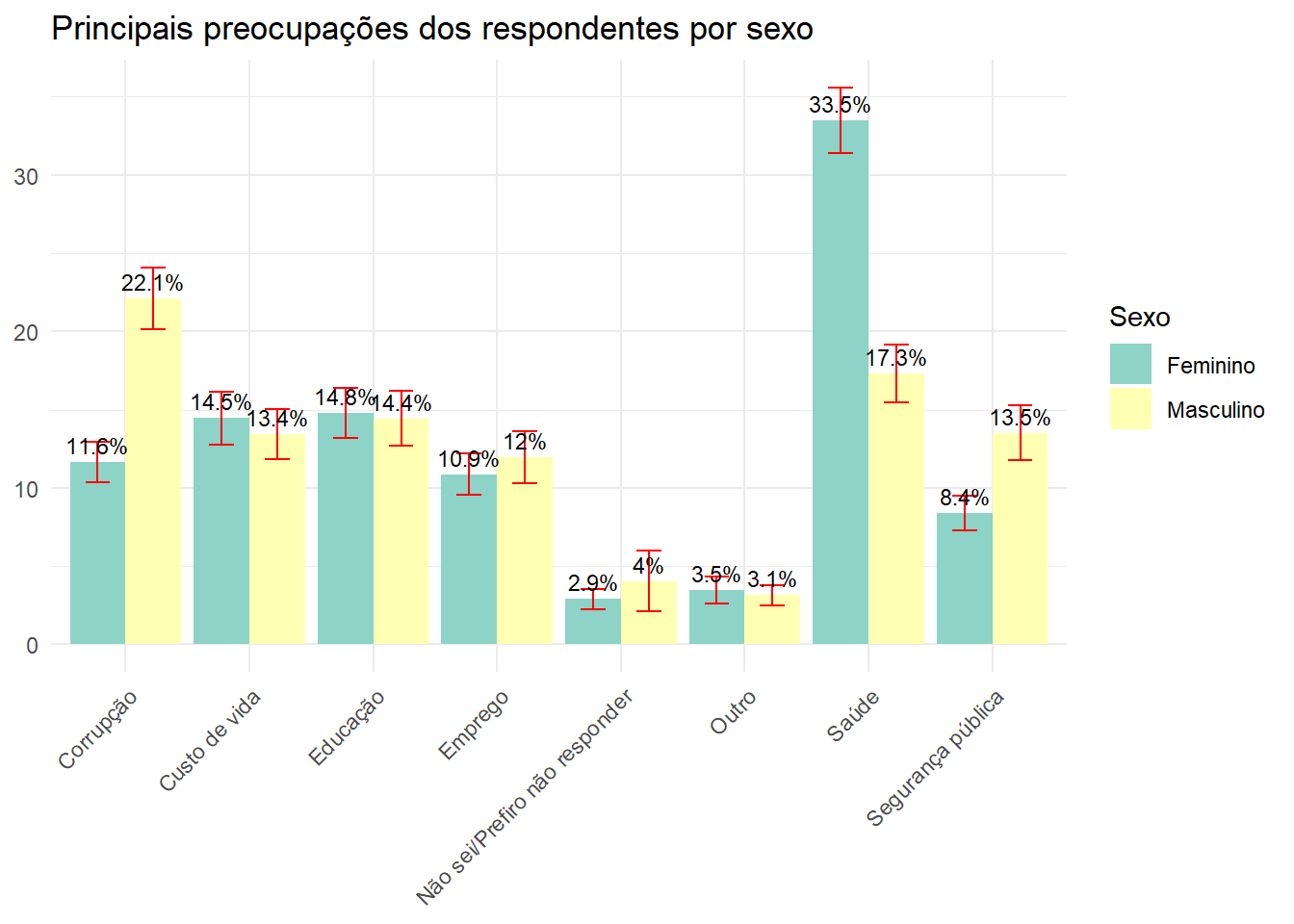
Qual a opinião da população brasileira sobre a redução maioridade penal por sexo?
opi_sexo <- data.rake.srvyr %>%
group_by(V02, P06) %>%
summarise(porcentagem = survey_prop()) |>
rename("Opinião" = P06, "Sexo" = V02)
ggplot(opi_sexo, aes(x = Opinião, y = (porcentagem*100), fill = Sexo)) +
geom_bar(stat = "identity", position = "dodge") +
geom_errorbar(aes(ymin = (porcentagem*100) - (porcentagem_se*100), ymax = (porcentagem*100) + (porcentagem_se*100)), width = 0.4, position = position_dodge(0.9), color = "red") +
labs(title = "Opinião sobre a redução maioridade penal por sexo", y = NULL, x = NULL) +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
scale_fill_brewer(palette = "Set3") +
geom_text(aes(label = paste0(round((porcentagem*100), 1), "%")), position = position_dodge(width = 0.9), vjust = -0.5, size = 3)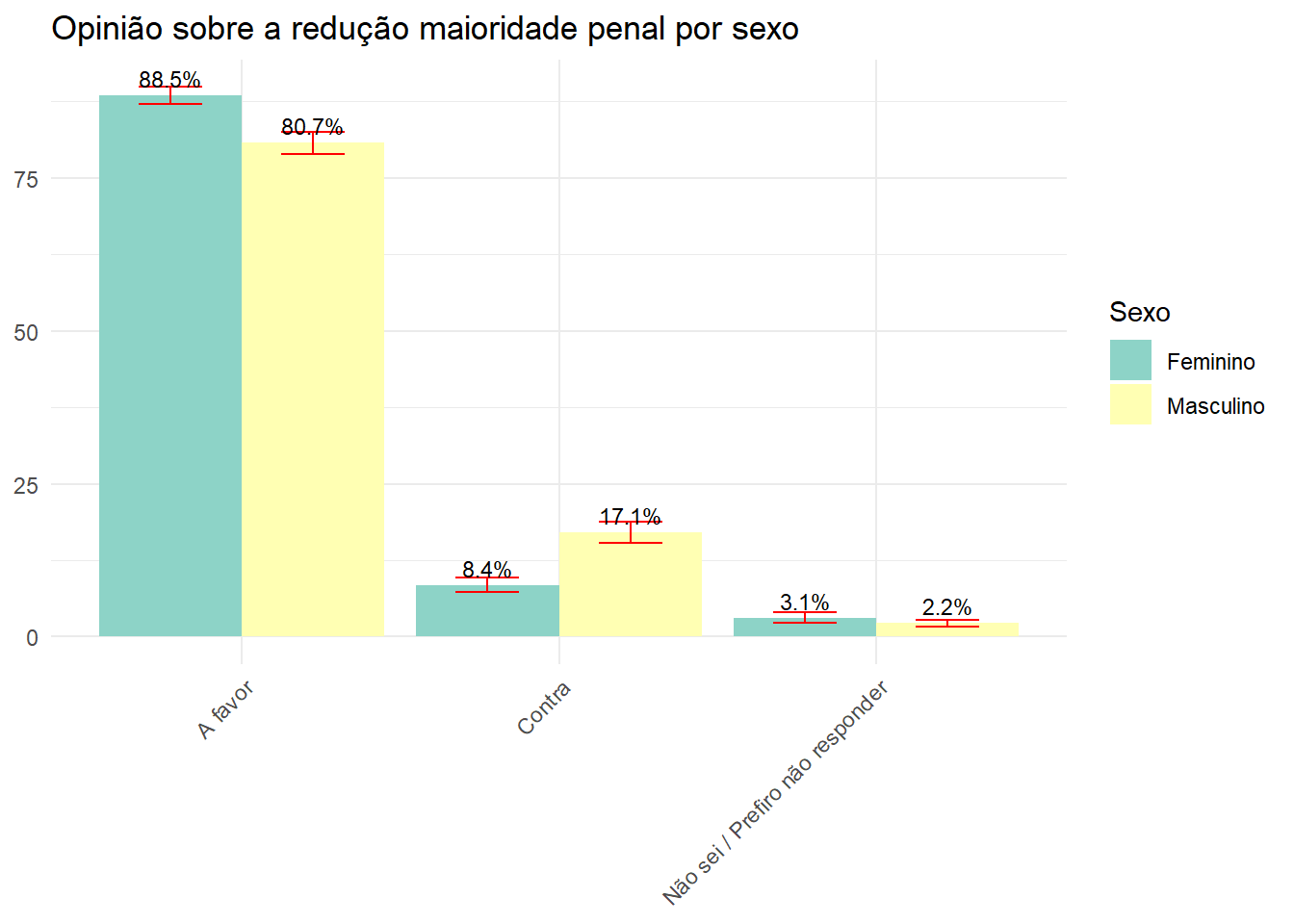
Qual a opinião da população brasileira sobre a redução maioridade penal por quem votou na última eleição (Voto no 1° Turno)?
opi_1_tur <- data.rake.srvyr %>%
group_by(VD_VOTO.TURNO1_, P06) %>%
summarise(porcentagem = survey_prop()) |>
rename("Opinião" = P06, "Voto no 1° Turno" = VD_VOTO.TURNO1_)
ggplot(opi_1_tur, aes(x = Opinião, y = (porcentagem*100), fill = `Voto no 1° Turno`)) +
geom_bar(stat = "identity", position = "dodge") +
geom_errorbar(aes(ymin = (porcentagem*100) - (porcentagem_se*100), ymax = (porcentagem*100) + (porcentagem_se*100)), width = 0.4, position = position_dodge(0.9), color = "red") +
labs(title = "Opinião sobre a redução maioridade penal por quem votou na última eleição (Voto no 1° Turno)", y = NULL, x = NULL) +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
scale_fill_brewer(palette = "Set3") +
geom_text(aes(label = paste0(round((porcentagem*100), 1), "%")), position = position_dodge(width = 0.9), vjust = -0.5, size = 3)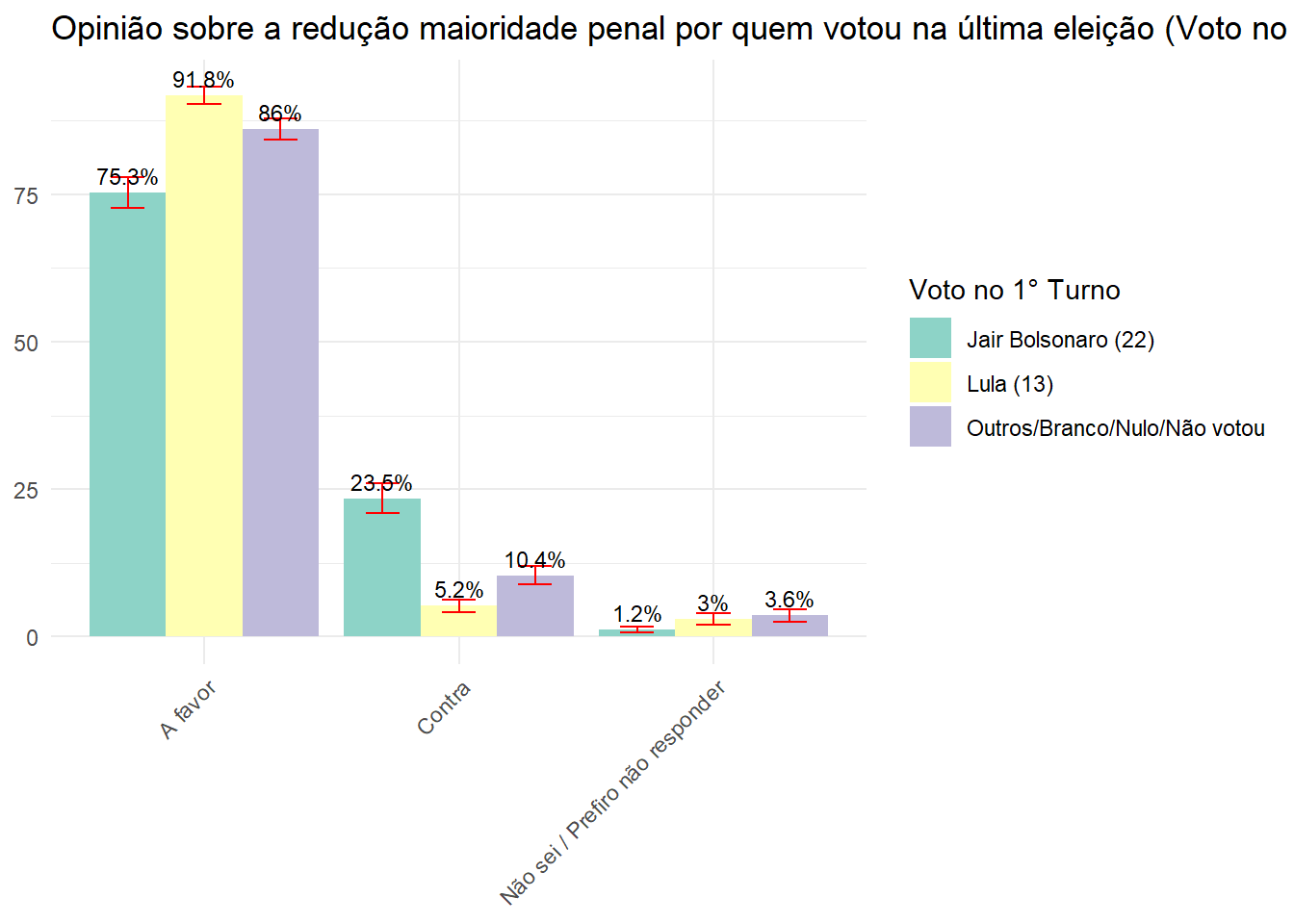
Qual a opinião da população brasileira sobre a redução maioridade penal por quem votou na última eleição (Voto no 2° Turno)?
opi_2_tur <- data.rake.srvyr %>%
group_by(VD_VOTO.TURNO2_, P06) %>%
summarise(porcentagem = survey_prop()) |>
rename("Opinião" = P06, "Voto no 2° Turno" = VD_VOTO.TURNO2_)
ggplot(opi_2_tur, aes(x = Opinião, y = (porcentagem*100), fill = `Voto no 2° Turno`)) +
geom_bar(stat = "identity", position = "dodge") +
geom_errorbar(aes(ymin = (porcentagem*100) - (porcentagem_se*100), ymax = (porcentagem*100) + (porcentagem_se*100)), width = 0.4, position = position_dodge(0.9), color = "red") +
labs(title = "Opinião sobre a redução maioridade penal por quem votou na última eleição (Voto no 2° Turno)", y = NULL, x = NULL) +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
scale_fill_brewer(palette = "Set3") +
geom_text(aes(label = paste0(round((porcentagem*100), 1), "%")), position = position_dodge(width = 0.9), vjust = -0.5, size = 3)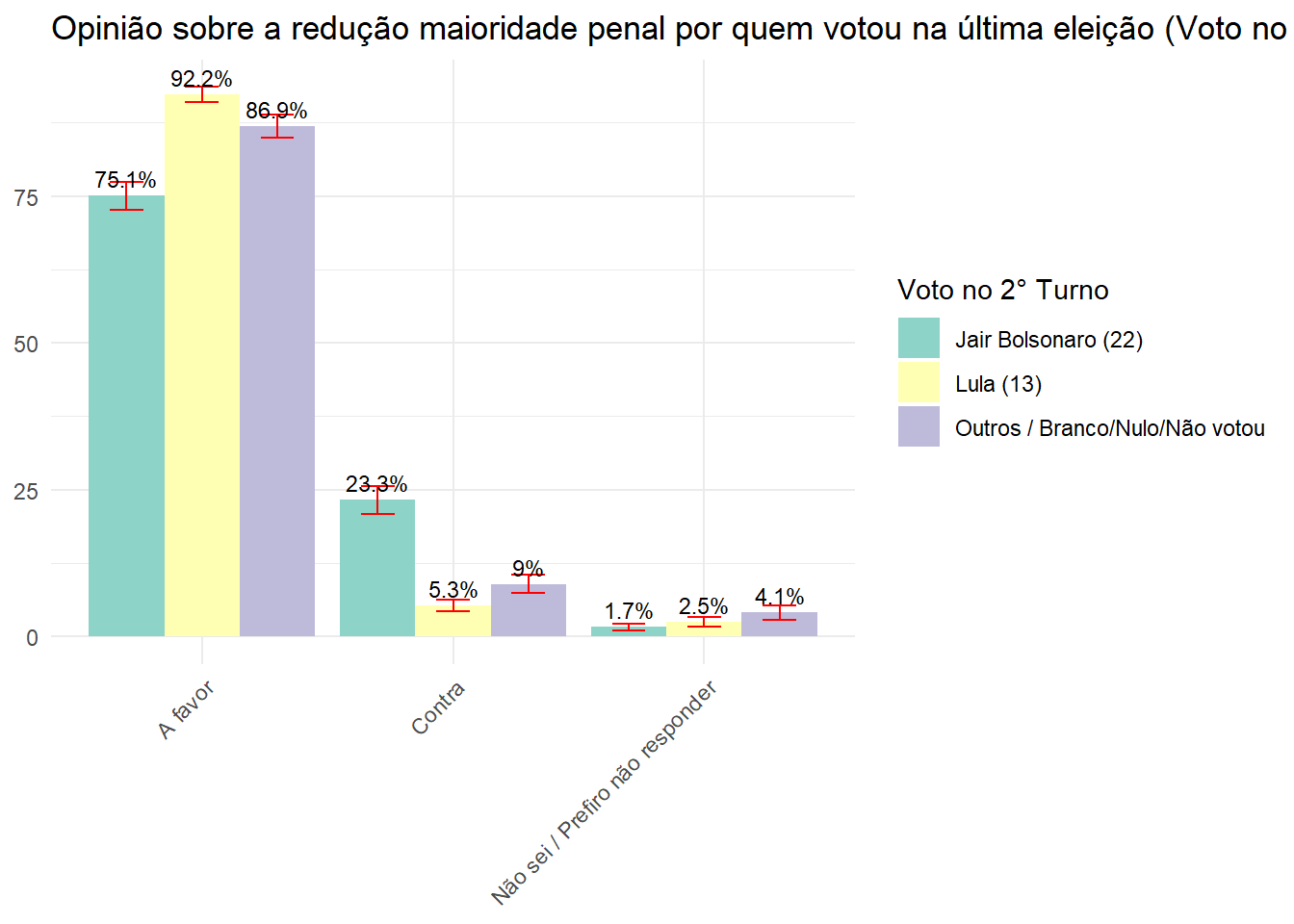
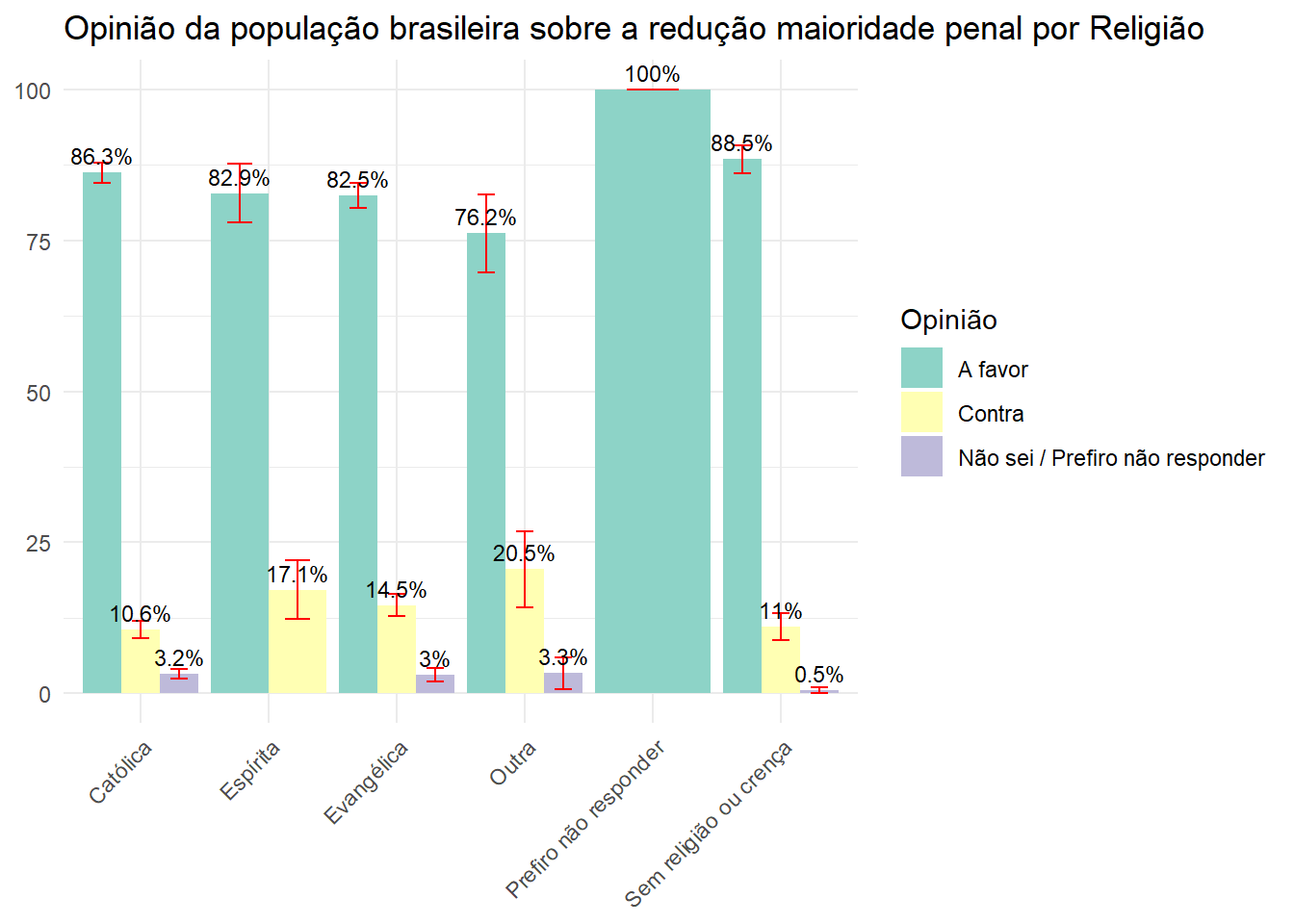
Qual a opinião da população brasileira sobre a redução maioridade penal por Religião?
opi_por_rel <- data.rake.srvyr %>%
group_by(V09, P06) %>%
summarise(porcentagem = survey_prop()) |>
rename("Religião" = V09, "Opinião" = P06)
ggplot(opi_por_rel, aes(x = Religião, y = (porcentagem*100), fill = Opinião)) +
geom_bar(stat = "identity", position = "dodge") +
geom_errorbar(aes(ymin = (porcentagem*100) - (porcentagem_se*100), ymax = (porcentagem*100) + (porcentagem_se*100)), width = 0.4, position = position_dodge(0.9), color = "red") +
labs(title = "Opinião da população brasileira sobre a redução maioridade penal por Religião", y = NULL, x = NULL) +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
scale_fill_brewer(palette = "Set3") +
geom_text(aes(label = paste0(round((porcentagem*100), 1), "%")), position = position_dodge(width = 0.9), vjust = -0.5, size = 3)